GPU
|
|
|
- Vakarė Petrauskas
- prieš 6 metus
- Peržiūrų:
Transkriptas
1 Įvadas į skaičiavimus su GPU Medžiagos šaltiniai: docs.nvidia.com/cuda/cuda-c-programming-guide/
2 GPU GPU angl. Graphical processing unit, skaičiavimų įrenginys, kuris pradžioje buvo skirtas grafikai skirtų skaičiavimų apdorojimui. GPGPU angl. General-purpose computing on GPUs, GPU panaudojimas bet kurių (nebūtinai grafikos apdorojimo) skaičiavimų atlikimui.
3 CPU ir GPU FLOPS
4 Specializuotų GPU atminties pralaidumas

5 CPU v/s GPU, pritaikymo pavyzdžių palyginimas (2009 m.) NVIDIA Corporation 2009
6 GPGPU Kaip to pasiekti programuotojui? CUDA OpenCL DirectCompute Tačiau pradėti reikia nuo architektūros...
7 GPU įrenginio architektūra Skaičiavimų atžvilgiu, GPU (ang. graphics processing unit) - tai lygiagretusis skaičiavimų įrenginys. Išskirkime pagrindinius aspektus, į kuriuos reikia atkreipti dėmesį, kai į GPU žiūrima kaip į skaičiavimų įrenginį: 1. Skaičiavimų vienetai (ALU) 2. Atminties struktūra
8 CPU ir GPU architektūrų supaprastintas palyginimas NVIDIA Corporation 2009
9 Skaičiavimų vienetai (ALU) 1. GPU susidaro iš N SM multiprocesorių (toliau SM, angl. streaming multiprocessor) 2. Vienas multiprocesorius turi N m branduolių, sudarytų iš skaičiavimų modulių. Moduliai gali būti skirtingi - tai priklauso nuo konkrečios plokštės GPU architektūros. 3. Visi skaičiavimai ir duomenų siuntimai yra atliekami porcijomis, specialiais gijų apdorojimo vienetais, kurie operuoja gijų porcijomis (angl. warp). 4. Programuotojo užduotis parašyti kodą taip, kad gijų porcijos veiktų efektyviai, remiantis jų veikimo principais ir NVIDIA rekomendacijomis.
10 Atminties struktūra 1. GPU turi pagrindinę atmintį duomenims talpinti, paprastai tai yra vieno gigabaito eilės dydžio atmintis. Iš jos skaityti ir į ją rašyti gali visi CUDA branduoliai lygiagrečiai. GPU pagrindinė atmintis išskaidyta į segmentus, jų dydis priklauso nuo GPU atminties magistralės dydžio. 2. Pagrindinė atmintis naudojama globaliajai ir lokaliajai atmintims saugoti. Jos skiriasi tik tuo, kad lokalioji yra rezervuota tam tikroms gijoms o iš globaliosios gali skaityti ir GPU ir CPU (kopijuojant). 3. Kiekvienas GPU multiprocesorius turi greitąją atmintį (padalintą į kelias rūšis), paprastai tai yra kilobaitų eilės dydžio atmintis. Duomenų nuskaitymas ir įrašymas šioje atmintyje yra žymiai greitesnis, nei pagrindinės atminties. 4. Greitąją atmintį galima suskaidyti į šiuos tipus: a) Registrai. Šiuo metu skaičiavimuose dalyvaujantiems duomenims talpinti skirta atmintis b) Bendroji atmintis. Yra prieinama skirtingų vieno multiprocesoriaus gijų, tačiau vieno multiprocesoriaus nėra prieinama kito multiprocesoriaus skaičiavimų moduliams. c) L1 cache atmintis automatizuota bendrosios atminties versija, kurios panaudojimu rūpinasi kompiliatorius. 5. L2 cache atmintis spartinančioji atmintis, kuri yra bendra visiems multiprocesoriams, greitesnę už pagrindinę bet lėtesnė už greitąją. 6. Bendros atminties siuntimai yra prieinami per taip vadinamus bankus (angl. bank). Skirtinguose bankuose siuntimai vykdomi lygiagrečiai, tačiau kiekvienas multiprocesorius turi ribota bankų skaičių. 7. Kiekvienas GPU multiprocesorius turi ribotą registrų skaičių. 8. Dar yra constant ir texture tipų atmintis, tačiau jų mes nenagrinėsime

11 Skirtingų atminties tipų prieinamumas
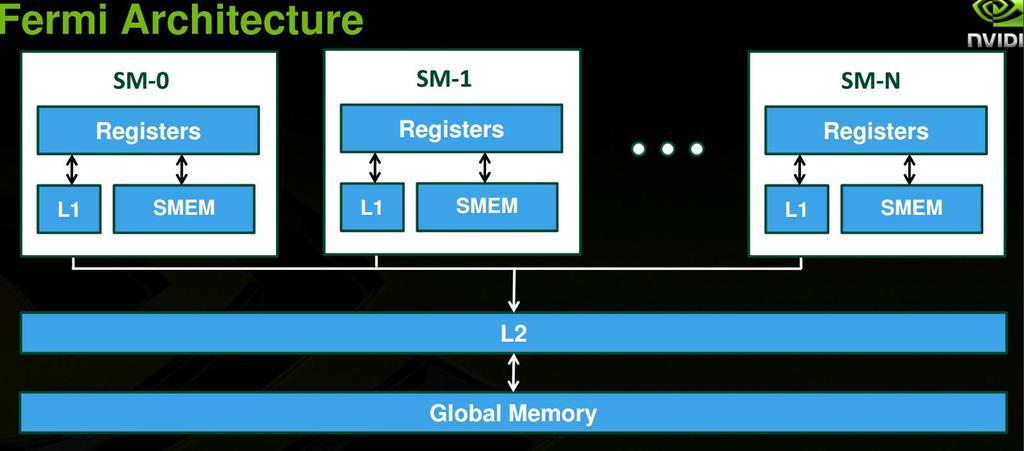
12 L2 spartinančioji atmintis

13 Pratimas: nurodykite, kur šioje schemoje randasi: 1. GPU L1 cache, 2. GPU bendroji atmintis, 3. GPU lokalioji atmintis, 4. GPU globalioji atmintis. NVIDIA Corporation 2009
14 Heterogeniniai skaičiavimai Heterogeniniai skaičiavimai tai skaičiavimai, kurie atliekami naudojant skirtingos rūšies skaičiavimų įrenginius: Host CPU ir jo atmintis (RAM, cache) Device GPU ir jos atmintis (device memory) Host Device


15 CPU ir GPU naudojimas Paprastai abiejų rūšių įrenginiai egzistuoja kartu ir bendrą programuotojui prieinama skaičiavimų terpę galima nagrinėti kaip heterogenišką. Mažiau skaičiavimų reikalaujančios ir blogiau išlygiagretinamos algoritmo dalys skaičiuojamos su CPU. Daugiausia skaičiavimų reikalaujantys algoritmų dalys (jeigu jos gerai išlygiagretinamos) skaičiuojamos su GPU
16 Įrenginio pavyzdys, NVIDIA Kepler K streaming processors/cores (SPs) organized as 15 streaming multiprocessors (SMs) Each SM contains 192 cores Memory size of the GPU system: 12 GB Clock speed of a core: 745 MHz

17 Heterogeniniai skaičiavimai #include <iostream> #include <algorithm> using namespace std; #define N 1024 #define RADIUS 3 #define BLOCK_SIZE 16 global void stencil_1d(int *in, int *out) { shared int temp[block_size + 2 * RADIUS]; int gindex = threadidx.x + blockidx.x * blockdim.x; int lindex = threadidx.x + RADIUS; // Read input elements into shared memory temp[lindex] = in[gindex]; if (threadidx.x < RADIUS) { temp[lindex - RADIUS] = in[gindex - RADIUS]; temp[lindex + BLOCK_SIZE] = in[gindex + BLOCK_SIZE]; } // Synchronize (ensure all the data is available) syncthreads(); // Apply the stencil int result = 0; for (int offset = -RADIUS ; offset <= RADIUS ; offset++) result += temp[lindex + offset]; Lygiagreti funkcija } // Store the result out[gindex] = result; void fill_ints(int *x, int n) { fill_n(x, n, 1); } int main(void) { int *in, *out; // host copies of a, b, c int *d_in, *d_out; // device copies of a, b, c int size = (N + 2*RADIUS) * sizeof(int); // Alloc space for host copies and setup values in = (int *)malloc(size); fill_ints(in, N + 2*RADIUS); out = (int *)malloc(size); fill_ints(out, N + 2*RADIUS); // Alloc space for device copies cudamalloc((void **)&d_in, size); cudamalloc((void **)&d_out, size); // Copy to device cudamemcpy(d_in, in, size, cudamemcpyhosttodevice); cudamemcpy(d_out, out, size, cudamemcpyhosttodevice); nuoseklus kodas // Launch stencil_1d() kernel on GPU stencil_1d<<<n/block_size,block_size>>>(d_in + RADIUS, d_out + RADIUS); } // Copy result back to host cudamemcpy(out, d_out, size, cudamemcpydevicetohost); // Cleanup free(in); free(out); cudafree(d_in); cudafree(d_out); return 0; lygiagretus kodas nuoseklus kodas
18 Supaprastina duomenų srauto schema PCI Bus 1. Duomenys iš CPU atmintis kopijuojami į GPU amtintį
19 Supaprastina duomenų srauto schema PCI Bus 1. Duomenys iš CPU atmintis kopijuojami į GPU amtintį 2. GPU programa užkraunama ir paleidžiama, kuo efektyviau išnaudojant spartinančiąją atmintį (cache)

 3.")
20 Supaprastina duomenų srauto schema PCI Bus 1. Duomenys iš CPU atmintis kopijuojami į GPU amtintį 2. GPU programa užkraunama ir paleidžiama, kuo efektyviau išnaudojant spartinančiąją atmintį (cache) 3. Rezultatas kopijuojamas iš GPU atminties į CPU amtintį
21 CUDA CUDA lygiagrečiųjų skaičiavimų platforma ir programavimo modelis CUDA skirta GPGPU skaičiavimams realizuoti Angl. Compute Unified Device Architecture, nepaisant šio akronimo tiesioginio vertimo, tai ne architektūra Skirtingai nuo kitokių priemonių (pvz. OpenCL) CUDA struktūra ir terminologija stipriai susieta su GPU architektūra, todėl GPGPU skaičiavimams suprasti ji tinka labai gerai.


22 CUDA programavimo principai Programuotojas apibrėžia užduočių blokus, kurias galima atlikinėti tarpusavyje nepriklausomai, paleidžia specialiąją funkciją-kernelį, visą kita daroma automatiškai. Programuotojas apibrėžia blokų dydį, jų skaičių ir loginį išsidėstymą Funkcijos-kernelio viduje programuotojas naudoja specialiuosius kintamuosius, kad nustatyti kiekvienai gijai praklausančius darbus
23 SIMT principas NVIDIA įvedė SIMT sąvoką, kuri gerai apibūdina skaičiavimus su CUDA. SIMT angl. Single Instruction Multiple Threads. Single instruction programuotojo akimis yra GPU funkcijoje esančios instrukcijos. Kiekvienas multiprocesorius sukuria, apdoroja, sudaro tvarkaraštį, paleidžia gijas grupėmis po 32 gijas, vadinsime jas gijų porcijomis (angl. warps). Vienoje gijų porcijoje visos gijos pradeda darbą vienu metu. Programuotojas turi siekti išlaikyti jų sinchnonišką veikimą (vengti išsišakojimo su if ir t.t). Nes kitu atveju kiekviena iš šakų yra vykdoma nuosekliai viena po kitos, o gijų dalis laukia. Kai multiprocesorius gauna vykdyti vieną arba daugiau užduočių blokų kiekvienas blokas išskaidomas į gijų porcijas ir kiekviena iš porcijų yra valdoma tvarkaraščio sudarymo ir vykdymo mechanizmais. Viena gijų porcija gali vykdyti tik vieną instrukciją, todėl reikia rūpintis, kad visos gijos vienoje porcijoje tuo pačiu metu atlikinėtų tą pačią instrukciją. Tokio inžinerinio sprendimo priežastimi galima laikyti skaičiavimų valdymo supaprastinimą, kadangi 32-jų gijų valdymui reikalingas tik vienas gijų valdymo mechanizmas (angl. control unit).

24 Instrukcijų eilių sudarymas
25 Compute capability Visi NVIDIA GPU įrenginiai charakterizuojami GPU kartos rodikliu skaičiavimų pajėgumu, angl. compute capability. GPU su didesniu skaičiavimų pajėgumu paprastai sumažina reikalavimus efektyvios programos kodo rašymui.
26 Paslinktas atminties nuskaitymas Viena gijų porcija nuskaito duomenis iš skirtingų pagrindinės atminties segmentų, pvz. Nuo 96 baito iki 224 (ne imtinai): Compute capability: 1. Tesla C Tesla C C Taigi, naujesniose GPU programuotojui nebereikia rūpintis atminties lygiavimu

27 Ko tikrai reikėtų vengti: atminties prieigos žingsniai Pvz.: gijų porcija nuskaito duomenis praleisdama kas antrą elementą: Compute capability: 1. Tesla C Tesla C C
28 CUDA gijų užimtumas (angl. occupancy) Didesniam GPU skaičiavimų greičiui pasiekti gijų skaičius turi buti didesnis už branduolių skaičių, nes kiekviena gija paprastai skaičiuoja tik viso laiko dalį, kitais laiko momentais ji nuskaito duomenis arba laukia del įvairių priežasčių (pvz. negali panaudoti duomenu po jų įrašymo į registrus 24 branduolio ciklus) Paleistų gijų skaičių riboja tai, kad vienas multiprocesorius gali paleisti ne daugiau 8 užduočių blokų Bendras paleistų gijų naudojamų registrų skaičius ir bendros atminties kiekis yra riboti vienam multiprocesriui Yra maksimalus gijų porcijų skaičius Paleistų (aktyvių) gijų porcijų (po 32 gijas) skaičiaus ir maksimalaus gijų porcijų skaičiaus santykis vadinamas CUDA gijų užimtumu (occupancy) Maksimalus gijų užimtumas leidžia optimaliai apkrauti duomenų nuskaitymo mechanizmus arba GPU skaičiavimų modulius. Skaičiuojant su GPU paprastai silpoji vieta (angl. bottleneck) yra būtent duomenų jūdėjimas. Daugiau informacijos
29 Kai kurie CUDA sintaksės elementai Raktažodis global GPU funkcijoms (kerneliams) deklaruoti. Pvz. global void mykernel(void) {... GPU funkcijos kvietimo specialiųjų parametrų (blokų tinklo ir bloko matmenų) nurodymas iškarto po funkcijos vardo. Pvz. mykernel<<<grid, threads>>>(... griddim, blockdim, blockidx threadidx kintamieji, kurie visada deklaruoti ir rezervuoti skaičiavimų paskirstymo tikslams. Visi jie yra prieinami GPU funkcijų viduje, jie turi tris laukus: x,y,z. Detaliau: griddim parodo blokų tinklo matmenis, jeigu blokų tinklas vienmatis griddim.x yra blokų skaičius blockdim parodo bloko matmenis, jeigu blokas yra vienmatis blockdim.x yra gijų skaičius (kiekviename bloke) blockidx parodo bloko numerius kiekviena iš krypčių, jeigu blokų tinklas yra vienmatis, tada blockidx.x yra tiesiog bloko numeris threadidx parodo gijų numerius tam tikro bloko viduje numerius kiekviena iš krypčių, jeigu blokas yra vienmatis, tada threadidx.x yra tiesiog gijos numeris bloke Jeigu blokų tinklas ir patys blokai yra vienmačiai, tada gijos numerį galima paskaičiuoti pagal formulę blockidx.x* blockdim.x + threadidx.x cudamalloc, cudafree funkcijos atminčiai GPU plokštėje išskirti/išvalyti cudamemcpy funkcija, reikalinga atminčiai kopijuoti iš/į GPU atmintį. Kryptį apibrėžia ketvirtasis argumentas, jis gali būti lygūs, pvz. cudamemcpydevicetohost (iš GPU atminties į CPU operatyviąją), cudamemcpyhosttodevice (atvirkščiai) ir kt. Sinchronizacijos funkcijos, pvz. syncthreads() gijų sinchronizavimas to pačio bloko viduje, kviečiama GPU funkcijoje. cudathreadsynchronize() priverčia CPU laukti, kol visi GPU kerneliai pabaigs savo darbą, kviečiamas CPU vykdomajame.
30 Toliau nagrinėsime sintaksės taikymo pavyzdžius Tolimesnės medžiagos tiesioginis šaltinis: /sc11-cuda-c-basics.pdf
31 Hello World! Medžagos tiesioginis šaltinis: CUDA C/C++ Basics int main(void) { } printf("hello World!\n"); return 0; Kodas be CUDA konstrukcijų NVIDIA kompiliatorius (nvcc) gali būti naudojamas be GPU skaičiavimams skirto kodo Output: $ nvcc hello_world. cu $ a.out Hello World! $
32 Hello World! Su įrenginiui skirtu kodu global void mykernel(void) { } int main(void) { mykernel<<<1,1>>>(); printf("hello World!\n"); return 0; } Du nauji sintaksės elementai
33 Hello World! Su įrenginiui skirtu kodu global void mykernel(void) { } CUDA C/C++ keyword global indicates a function that: Runs on the device Is called from host code nvcc separates source code into host and device components Device functions (e.g. mykernel()) processed by NVIDIA compiler Host functions (e.g. main()) processed by standard host compiler gcc, cl.exe
34 Hello World! with Device COde mykernel<<<1,1>>>(); Triple angle brackets mark a call from host code to device code Also called a kernel launch We ll return to the parameters (1,1) in a moment That s all that is required to execute a function on the GPU!
35 Hello World! with Device Code global void mykernel(void){ } int main(void) { } mykernel<<<1,1>>>(); printf("hello World!\n"); return 0; mykernel() does nothing, somewhat anticlimactic! Output: $ nvcc hello.cu $ a.out Hello World! $
36 Parallel Programming in CUDA C/C++ But wait GPU computing is about massive parallelism! We need a more interesting example We ll start by adding two integers and build up to vector addition a b c
37 Addition on the Device A simple kernel to add two integers global void add(int *a, int *b, int *c) { } *c = *a + *b; As before global is a CUDA C/C++ keyword meaning add() will execute on the device add() will be called from the host
38 Addition on the Device Note that we use pointers for the variables { global void add(int *a, int *b, int *c) } *c = *a + *b; add() runs on the device, so a, b and c must point to device memory We need to allocate memory on the GPU
39 Memory Management Host and device memory are separate entities Device pointers point to GPU memory May be passed to/from host code May not be dereferenced in host code Host pointers point to CPU memory May be passed to/from device code May not be dereferenced in device code Simple CUDA API for handling device memory cudamalloc(), cudafree(), cudamemcpy() Similar to the C equivalents malloc(), free(), memcpy()
40 Addition on the Device: add() Returning to our add() kernel { global void add(int *a, int *b, int *c) } *c = *a + *b; Let s take a look at main()
41 Addition on the Device: main() int main(void) { int a, b, c; int *d_a, *d_b, *d_c; int size = sizeof(int); // host copies of a, b, c // device copies of a, b, c // Allocate space for device copies of a, b, c cudamalloc((void **)&d_a, size); cudamalloc((void **)&d_b, size); cudamalloc((void **)&d_c, size); // Setup input values a = 2; b = 7;
42 Addition on the Device: main() // Copy inputs to device cudamemcpy(d_a, &a, size, cudamemcpyhosttodevice); cudamemcpy(d_b, &b, size, cudamemcpyhosttodevice); // Launch add() kernel on GPU add<<<1,1>>>(d_a, d_b, d_c); // Copy result back to host cudamemcpy(&c, d_c, size, cudamemcpydevicetohost); } // Cleanup cudafree(d_a); cudafree(d_b); cudafree(d_c); return 0;
43 CONCEPTS Heterogeneous Computing Blocks Threads Indexing Shared memory syncthreads() Asynchronous operation RUNNING IN PARALLEL Handling errors Managing devices
44 Moving to Parallel GPU computing is about massive parallelism So how do we run code in parallel on the device? add<<< 1, 1 >>>(); add<<< N, 1 >>>(); Instead of executing add() once, execute N times in parallel
45 Vector Addition on the Device With add() running in parallel we can do vector addition Terminology: each parallel invocation of add() is referred to as a block The set of blocks is referred to as a grid Each invocation can refer to its block index using blockidx.x global void add(int *a, int *b, int *c) { } c[blockidx.x] = a[blockidx.x] + b[blockidx.x]; By using blockidx.x to index into the array, each block handles a different index
46 Vector Addition on the Device global void add(int *a, int *b, int *c) { } c[blockidx.x] = a[blockidx.x] + b[blockidx.x]; On the device, each block can execute in parallel: Block 0 Block 1 Block 2 Block 3 c[0] = a[0] + b[0]; c[1] = a[1] + b[1]; c[2] = a[2] + b[2]; c[3] = a[3] + b[3];
47 Vector Addition on the Device: add() Returning to our parallelized add() kernel global void add(int *a, int *b, int *c) { } c[blockidx.x] = a[blockidx.x] + b[blockidx.x]; Let s take a look at main()
48 Vector Addition on the Device: #define N 512 int main(void) { int *a, *b, *c; // host copies of a, b, c int *d_a, *d_b, *d_c; // device copies of a, b, c int size = N * sizeof(int); // Alloc space for device copies of a, b, c cudamalloc((void **)&d_a, size); cudamalloc((void **)&d_b, size); cudamalloc((void **)&d_c, size); // Alloc space for host copies of a, b, c and setup input values a = (int *)malloc(size); random_ints(a, N); b = (int *)malloc(size); random_ints(b, N); c = (int *)malloc(size);
49 Vector Addition on the Device: main() // Copy inputs to device cudamemcpy(d_a, a, size, cudamemcpyhosttodevice); cudamemcpy(d_b, b, size, cudamemcpyhosttodevice); // Launch add() kernel on GPU with N blocks add<<<n,1>>>(d_a, d_b, d_c); // Copy result back to host cudamemcpy(c, d_c, size, cudamemcpydevicetohost); } // Cleanup free(a); free(b); free(c); cudafree(d_a); cudafree(d_b); cudafree(d_c); return 0;
50 Review (1 of 2) Difference between host and device Host Device CPU GPU Using global to declare a function as device code Executes on the device Called from the host Passing parameters from host code to a device function
51 Review (2 of 2) Basic device memory management cudamalloc() cudamemcpy() cudafree() Launching parallel kernels Launch N copies of add() with add<<<n,1>>>( ); Use blockidx.x to access block index
52 CONCEPTS Heterogeneous Computing Blocks Threads Indexing Shared memory syncthreads() Asynchronous operation INTRODUCING THREADS Handling errors Managing devices
53 CUDA Threads Terminology: a block can be split into parallel threads Let s change add() to use parallel threads instead of parallel blocks global void add(int *a, int *b, int *c) { } c[threadidx.x] = a[threadidx.x] + b[threadidx.x]; We use threadidx.x instead of blockidx.x Need to make one change in main()
54 Vector Addition Using Threads: #define N 512 int main(void) { int *a, *b, *c; int *d_a, *d_b, *d_c; int size = N * sizeof(int); // host copies of a, b, c // device copies of a, b, c // Alloc space for device copies of a, b, c cudamalloc((void **)&d_a, size); cudamalloc((void **)&d_b, size); cudamalloc((void **)&d_c, size); // Alloc space for host copies of a, b, c and setup input values a = (int *)malloc(size); random_ints(a, N); b = (int *)malloc(size); random_ints(b, N); c = (int *)malloc(size);
55 Vector Addition Using Threads: main() // Copy inputs to device cudamemcpy(d_a, a, size, cudamemcpyhosttodevice); cudamemcpy(d_b, b, size, cudamemcpyhosttodevice); // Launch add() kernel on GPU with N threads add<<<1,n>>>(d_a, d_b, d_c); // Copy result back to host cudamemcpy(c, d_c, size, cudamemcpydevicetohost); } // Cleanup free(a); free(b); free(c); cudafree(d_a); cudafree(d_b); cudafree(d_c); return 0;
56 CONCEPTS Heterogeneous Computing Blocks Threads Indexing Shared memory syncthreads() Asynchronous operation COMBINING THREADS AND BLOCKS Handling errors Managing devices
57 Combining Blocks and Threads We ve seen parallel vector addition using: Many blocks with one thread each One block with many threads Let s adapt vector addition to use both blocks and threads Why? We ll come to that First let s discuss data indexing
58 Indexing Arrays with Blocks and Threads No longer as simple as using blockidx.x and threadidx.x Consider indexing an array with one element per thread (8 threads/block) threadidx.x threadidx.x threadidx.x threadidx.x blockidx.x = 0 blockidx.x = 1 blockidx.x = 2 blockidx.x = 3 With M threads/block a unique index for each thread is given by: int index = threadidx.x + blockidx.x * M;
59 Indexing Arrays: Example Which thread will operate on the red element? M = 8 threadidx.x = blockidx.x = 2 int index = threadidx.x + blockidx.x * M; = * 8; = 21;
60 Vector Addition with Blocks and Threads Use the built-in variable blockdim.x for threads per block int index = threadidx.x + blockidx.x * blockdim.x; Combined version of add() to use parallel threads and parallel blocks global void add(int *a, int *b, int *c) { int index = threadidx.x + blockidx.x * blockdim.x; c[index] = a[index] + b[index]; } What changes need to be made in main()?
61 Addition with Blocks and Threads: main() #define N (2048*2048) #define THREADS_PER_BLOCK 512 int main(void) { int *a, *b, *c; int *d_a, *d_b, *d_c; int size = N * sizeof(int); // host copies of a, b, c // device copies of a, b, c // Alloc space for device copies of a, b, c cudamalloc((void **)&d_a, size); cudamalloc((void **)&d_b, size); cudamalloc((void **)&d_c, size); // Alloc space for host copies of a, b, c and setup input values a = (int *)malloc(size); random_ints(a, N); b = (int *)malloc(size); random_ints(b, N); c = (int *)malloc(size);
62 Addition with Blocks and Threads: // Copy inputs to device cudamemcpy(d_a, a, size, cudamemcpyhosttodevice); cudamemcpy(d_b, b, size, cudamemcpyhosttodevice); // Launch add() kernel on GPU add<<<n/threads_per_block,,threads_per_block>>>(d_a, d_b, d_c); // Copy result back to host cudamemcpy(c, d_c, size, cudamemcpydevicetohost); } // Cleanup free(a); free(b); free(c); cudafree(d_a); cudafree(d_b); cudafree(d_c); return 0;
63 Handling Arbitrary Vector Sizes Typical problems are not friendly multiples of blockdim.x Avoid accessing beyond the end of the arrays: global void add(int *a, int *b, int *c, int n) { int index = threadidx.x + blockidx.x * blockdim.x; if (index < n) c[index] = a[index] + b[index]; } Update the kernel launch: add<<<(n + M-1) / M,M>>>(d_a, d_b, d_c, N);
64 Why Bother with Threads? Threads seem unnecessary They add a level of complexity What do we gain? Unlike parallel blocks, threads have mechanisms to: Communicate Synchronize To look closer, we need a new example
65 CONCEPTS Heterogeneous Computing Blocks Threads Indexing Shared memory syncthreads() Asynchronous operation COOPERATING THREADS Handling errors Managing devices
66 1D Stencil Consider applying a 1D stencil to a 1D array of elements Each output element is the sum of input elements within a radius If radius is 3, then each output element is the sum of 7 input elements: radius radius
67 Implementing Within a Block Each thread processes one output element blockdim.x elements per block Input elements are read several times With radius 3, each input element is read seven times
68 Sharing Data Between Threads Terminology: within a block, threads share data via shared memory Extremely fast on-chip memory, user-managed Declare using shared, allocated per block Data is not visible to threads in other blocks
69 Implementing With Shared Memory Cache data in shared memory Read (blockdim.x + 2 * radius) input elements from global memory to shared memory Compute blockdim.x output elements Write blockdim.x output elements to global memory Each block needs a halo of radius elements at each boundary halo on left halo on right blockdim.x NVIDIA output 2013elements
70 Stencil Kernel global void stencil_1d(int *in, int *out) { shared int temp[block_size + 2 * RADIUS]; int gindex = threadidx.x + blockidx.x * blockdim.x; int lindex = threadidx.x + RADIUS; // Read input elements into shared memory temp[lindex] = in[gindex]; if (threadidx.x < RADIUS) { temp[lindex - RADIUS] = in[gindex - RADIUS]; temp[lindex + BLOCK_SIZE] = in[gindex + BLOCK_SIZE]; }
71 Stencil Kernel // Apply the stencil int result = 0; for (int offset = -RADIUS ; offset <= RADIUS ; offset++) result += temp[lindex + offset]; } // Store the result out[gindex] = result;
72 Data Race! The stencil example will not work Suppose thread 15 reads the halo before thread 0 has fetched it temp[lindex] = in[gindex]; if (threadidx.x < RADIUS) { } Store at temp[18] temp[lindex RADIUS = in[gindex RADIUS]; temp[lindex + BLOCK_SIZE] = in[gindex + BLOCK_SIZE]; Skipped, threadidx > RADIUS int result = 0; result += temp[lindex + 1]; Load from temp[19]
73 syncthreads() void syncthreads(); Synchronizes all threads within a block Used to prevent RAW / WAR / WAW hazards All threads must reach the barrier In conditional code, the condition must be uniform across the block
74 Stencil Kernel global void stencil_1d(int *in, int *out) { shared int temp[block_size + 2 * RADIUS]; int gindex = threadidx.x + blockidx.x * blockdim.x; int lindex = threadidx.x + radius; // Read input elements into shared memory temp[lindex] = in[gindex]; if (threadidx.x < RADIUS) { temp[lindex RADIUS] = in[gindex RADIUS]; temp[lindex + BLOCK_SIZE] = in[gindex + BLOCK_SIZE]; } // Synchronize (ensure all the data is available) syncthreads();
75 Stencil Kernel // Apply the stencil int result = 0; for (int offset = -RADIUS ; offset <= RADIUS ; offset++) result += temp[lindex + offset]; } // Store the result out[gindex] = result;
76 Review (1 of 2) Launching parallel threads Launch N blocks with M threads per block with kernel<<<n,m>>>( ); Use blockidx.x to access block index within grid Use threadidx.x to access thread index within block Allocate elements to threads: int index = threadidx.x + blockidx.x * blockdim.x;
77 Review (2 of 2) Use shared to declare a variable/array in shared memory Data is shared between threads in a block Not visible to threads in other blocks Use syncthreads() as a barrier Use to prevent data hazards
78 CONCEPTS Heterogeneous Computing Blocks Threads Indexing Shared memory syncthreads() Asynchronous operation MANAGING THE DEVICE Handling errors Managing devices
79 Coordinating Host & Device Kernel launches are asynchronous Control returns to the CPU immediately CPU needs to synchronize before consuming the results cudamemcpy() cudamemcpyasync() cudadevicesynchro nize() Blocks the CPU until the copy is complete Copy begins when all preceding CUDA calls have completed Asynchronous, does not block the CPU Blocks the CPU until all preceding CUDA calls have completed
80 Reporting Errors All CUDA API calls return an error code (cudaerror_t) Error in the API call itself OR Error in an earlier asynchronous operation (e.g. kernel) Get the error code for the last error: cudaerror_t cudagetlasterror(void) Get a string to describe the error: char *cudageterrorstring(cudaerror_t) printf("%s\n", cudageterrorstring(cudagetlasterror()));
81 Device Management Application can query and select GPUs cudagetdevicecount(int *count) cudasetdevice(int device) cudagetdevice(int *device) cudagetdeviceproperties(cudadeviceprop *prop, int device) Multiple threads can share a device A single thread can manage multiple devices cudasetdevice(i) to select current device cudamemcpy( ) for peer-to-peer copies requires OS and device support
82 Introduction to CUDA C/C++ What have we learned? Write and launch CUDA C/C++ kernels global, blockidx.x, threadidx.x, <<<>>> Manage GPU memory cudamalloc(), cudamemcpy(), cudafree() Manage communication and synchronization shared, syncthreads() cudamemcpy() vs cudamemcpyasync(), cudadevicesynchronize()
83 Compute Capability The compute capability of a device describes its architecture, e.g. Number of registers Sizes of memories Features & capabilities Compute Capability Selected Features (see CUDA C Programming Guide for complete list) The following presentations concentrate on Fermi devices Compute Capability >= 2.0 Tesla models 1.0 Fundamental CUDA support Double precision, improved memory accesses, atomics 2.0 Caches, fused multiply-add, 3D grids, surfaces, ECC, P2P, concurrent kernels/copies, function pointers, recursion 10-series 20-series
 Bloc k (2,0, 0) Bloc k (2,1, 0) Built-in variables: threadidx blockidx blockdim griddim Block (1,1,0) Thre ad (0,0, 0) Thre ad (0,1, 0) Thre ad (1,0, 0) Thre ad (1,1, 0) Thre ad (2,0,")
84 IDs and Dimensions A kernel is launched as a grid of blocks of threads blockidx and threadidx are 3D We showed only one dimension (x) Device Grid 1 Bloc k (0,0, 0) Bloc k (0,1, 0) Bloc k (1,0, 0) Bloc k (1,1, 0) Bloc k (2,0, 0) Bloc k (2,1, 0) Built-in variables: threadidx blockidx blockdim griddim Block (1,1,0) Thre ad (0,0, 0) Thre ad (0,1, 0) Thre ad (1,0, 0) Thre ad (1,1, 0) Thre ad (2,0, 0) Thre ad (2,1, 0) Thre ad (3,0, 0) Thre ad (3,1, 0) Thre ad (4,0, 0) Thre ad (4,1, 0) Thre ad (0,2, 0) Thre ad (1,2, 0) Thre ad (2,2, 0) Thre ad (3,2, 0) Thre ad (4,2, 0)
85 Textures Read-only object Dedicated cache Dedicated filtering hardware (Linear, bilinear, trilinear) Addressable as 1D, 2D or 3D (2.5, 0.5) (1.0, 1.0) Out-of-bounds address handling (Wrap, clamp)
86 Topics we skipped We skipped some details, you can learn more: CUDA Programming Guide CUDA Zone tools, training, webinars and more developer.nvidia.com/cuda Need a quick primer for later: Multi-dimensional indexing Textures
Programų sistemų inžinerija Saulius Ragaišis, VU MIF
 Programų sistemų inžinerija 2014-02-12 Saulius Ragaišis, VU MIF saulius.ragaisis@mif.vu.lt SWEBOK evoliucija Nuo SWEBOK Guide to the Software Engineering Body of Knowledge, 2004 Version. IEEE, 2004. prie
Programų sistemų inžinerija 2014-02-12 Saulius Ragaišis, VU MIF saulius.ragaisis@mif.vu.lt SWEBOK evoliucija Nuo SWEBOK Guide to the Software Engineering Body of Knowledge, 2004 Version. IEEE, 2004. prie
Vienlusčių įtaisų projektavimas
 Vienlusčių įtaisų projektavimas 5 paskaita Baigtiniai būsenų automatai Baigtinis būsenų automatas: angl. Finite State Machine (FSM) FSM yra nuosekliai būsenas keičiantis automatas su "atsitiktine" kitos
Vienlusčių įtaisų projektavimas 5 paskaita Baigtiniai būsenų automatai Baigtinis būsenų automatas: angl. Finite State Machine (FSM) FSM yra nuosekliai būsenas keičiantis automatas su "atsitiktine" kitos
DBVS realizavimas Pagrindiniai DBVS komponentai Duomenų saugojimas diske Paruošė J.Skučas
 DBVS realizavimas Pagrindiniai DBVS komponentai Duomenų saugojimas diske Paruošė J.Skučas Seminaro tikslai Trumpai apžvelgti pagrindinius DBVS komponentus Detaliai nagrinėjami optimalaus duomenų dėstymo
DBVS realizavimas Pagrindiniai DBVS komponentai Duomenų saugojimas diske Paruošė J.Skučas Seminaro tikslai Trumpai apžvelgti pagrindinius DBVS komponentus Detaliai nagrinėjami optimalaus duomenų dėstymo
AB Linas Agro Group 2018 m. spalio 31 d. eilinio visuotinio akcininkų susirinkimo BENDRASIS BALSAVIMO BIULETENIS GENERAL VOTING BALLOT at Annual Gener
 1 AKCININKAS SHAREHOLDER FIZINIS ASMUO / NATURAL PERSON Vardas, pavardė Name, surname Asmens kodas: Personal code: JURIDINIS ASMUO / LEGAL PERSON Juridinio asmens pavadinimas Name of legal person Juridinio
1 AKCININKAS SHAREHOLDER FIZINIS ASMUO / NATURAL PERSON Vardas, pavardė Name, surname Asmens kodas: Personal code: JURIDINIS ASMUO / LEGAL PERSON Juridinio asmens pavadinimas Name of legal person Juridinio
Microsoft Word - 15_paskaita.doc
 15 PASKAITA Turinys: Išimtys Išimtys (exceptions) programos vykdymo metu kylančios klaidingos situacijos, nutraukiančios programos darbą (pavyzdžiui, dalyba iš nulio, klaida atveriant duomenų failą, indekso
15 PASKAITA Turinys: Išimtys Išimtys (exceptions) programos vykdymo metu kylančios klaidingos situacijos, nutraukiančios programos darbą (pavyzdžiui, dalyba iš nulio, klaida atveriant duomenų failą, indekso
skaitiniai metodai 1
 Lygiagretusis programavimas doc. dr. Vadimas Starikovičius 4-oji paskaita OpenMP programavimo standartas. Programavimo modelis. OpenMP konstrukcijos. PThreads: Hello, world! pavyzdys #include
Lygiagretusis programavimas doc. dr. Vadimas Starikovičius 4-oji paskaita OpenMP programavimo standartas. Programavimo modelis. OpenMP konstrukcijos. PThreads: Hello, world! pavyzdys #include
Java esminės klasės, 1 dalis Išimtys, Įvestis/išvestis
 Java esminės klasės, 1 dalis Išimtys, Įvestis/išvestis Klaidų apdorojimas C kalboje If (kazkokia_salyga) { klaidos_apdorojimas(); return... } Tokio kodo apimtis galėdavo sekti iki 70-80proc. Klaidų/išimčių
Java esminės klasės, 1 dalis Išimtys, Įvestis/išvestis Klaidų apdorojimas C kalboje If (kazkokia_salyga) { klaidos_apdorojimas(); return... } Tokio kodo apimtis galėdavo sekti iki 70-80proc. Klaidų/išimčių
Slide 1
 Duomenų struktūros ir algoritmai 2 paskaita 2019-02-13 Algoritmo sąvoka Algoritmas tai tam tikra veiksmų seka, kurią reikia atlikti norint gauti rezultatą. Įvesties duomenys ALGORITMAS Išvesties duomenys
Duomenų struktūros ir algoritmai 2 paskaita 2019-02-13 Algoritmo sąvoka Algoritmas tai tam tikra veiksmų seka, kurią reikia atlikti norint gauti rezultatą. Įvesties duomenys ALGORITMAS Išvesties duomenys
skaitiniai metodai 1
 Lygiagretusis programavimas doc. dr. Vadimas Starikovičius 6-oji paskaita Paskirstytosios atminties lygiagretusis programavimas. MPI programavimo biblioteka. Pagrindinės MPI funkcijos. Paskirstytos atminties
Lygiagretusis programavimas doc. dr. Vadimas Starikovičius 6-oji paskaita Paskirstytosios atminties lygiagretusis programavimas. MPI programavimo biblioteka. Pagrindinės MPI funkcijos. Paskirstytos atminties
PowerPoint Presentation
 Programų sistemų inžinerija 2018-02-07 Saulius Ragaišis, VU MIF saulius.ragaisis@mif.vu.lt Klausytojai: Susipažinimas Išklausyti programų sistemų inžinerijos kursai Profesinė patirtis Dabar klausomi pasirenkami
Programų sistemų inžinerija 2018-02-07 Saulius Ragaišis, VU MIF saulius.ragaisis@mif.vu.lt Klausytojai: Susipažinimas Išklausyti programų sistemų inžinerijos kursai Profesinė patirtis Dabar klausomi pasirenkami
Masyvas su C++ Užduotys. Išsiaiškinkite kodą (jei reikia pataisykite) ir paleiskite per programą. Ciklo skaitliuko įrašymas į vienmatį masyvą: #includ
 ir paleiskite per programą. Ciklo skaitliuko įrašymas į vienmatį masyvą: #includ") Masyvas su C++ Užduotys. Išsiaiškinkite kodą (jei reikia pataisykite) ir paleiskite per programą. Ciklo skaitliuko įrašymas į vienmatį masyvą: #include main() int mas[100]; int k; for (int
Masyvas su C++ Užduotys. Išsiaiškinkite kodą (jei reikia pataisykite) ir paleiskite per programą. Ciklo skaitliuko įrašymas į vienmatį masyvą: #include main() int mas[100]; int k; for (int
DB sukūrimas ir užpildymas duomenimis
 DB sukūrimas ir užpildymas duomenimis Duomenų bazės kūrimas Naujas bendrąsias DB kuria sistemos administratorius. Lokalias DB gali kurti darbo stoties vartotojasadministratorius. DB kuriama: kompiuterio
DB sukūrimas ir užpildymas duomenimis Duomenų bazės kūrimas Naujas bendrąsias DB kuria sistemos administratorius. Lokalias DB gali kurti darbo stoties vartotojasadministratorius. DB kuriama: kompiuterio
AB Linas Agro Group 2018 m. spalio 31 d. eilinio visuotinio akcininkų susirinkimo BENDRASIS BALSAVIMO BIULETENIS GENERAL VOTING BALLOT at Annual Gener
 AKCININKAS THE SHAREHOLDER FIZINIS ASMUO / NATURAL PERSON Vardas, pavardė Name, surname Asmens kodas Personal code JURIDINIS ASMUO / LEGAL PERSON Juridinio asmens pavadinimas Name of legal person Juridinio
AKCININKAS THE SHAREHOLDER FIZINIS ASMUO / NATURAL PERSON Vardas, pavardė Name, surname Asmens kodas Personal code JURIDINIS ASMUO / LEGAL PERSON Juridinio asmens pavadinimas Name of legal person Juridinio
Pardavimų aplikacija (Microsoft Dynamics AX (Axapta) sistemai) Diegimo instrukcija bifree.lt qlik.com
 sistemai) Diegimo instrukcija bifree.lt qlik.com") Pardavimų aplikacija (Microsoft Dynamics AX (Axapta) sistemai) Diegimo instrukcija bifree.lt qlik.com Microsoft Dynamics AX (Axapta) sistemai 2 Kaip įsidiegti Diegimo žingsniai: 1. Atsisiųsti ir įsidiegti
Pardavimų aplikacija (Microsoft Dynamics AX (Axapta) sistemai) Diegimo instrukcija bifree.lt qlik.com Microsoft Dynamics AX (Axapta) sistemai 2 Kaip įsidiegti Diegimo žingsniai: 1. Atsisiųsti ir įsidiegti
Priedai
 Priedai Priedas Nr. 3 Įvesti duomenys Na- smūgių dažnumas į 1km' Na= 2 v 4 4 C2= 1 - objekto konstrukcija L- objekto ilgis L= 24 C3= 1 - objekto vertė W- objekto plotis W= 12 C4= 1 - žmonių kiekis objekte
Priedai Priedas Nr. 3 Įvesti duomenys Na- smūgių dažnumas į 1km' Na= 2 v 4 4 C2= 1 - objekto konstrukcija L- objekto ilgis L= 24 C3= 1 - objekto vertė W- objekto plotis W= 12 C4= 1 - žmonių kiekis objekte
AVK SUPA PLUS COUPLING 621/61 Tensile, for PE and PVC pipes, NF approved EPDM sealing 001 AVK Supa Plus is a range of tensile couplings, flange adapto
 AVK SUPA PUS COUPING 1/61 Tensile, for PE and PVC pipes, NF approved EPM sealing AVK Supa Plus is a range of tensile couplings, flange adaptors and end caps dedicated for PE and upvc pipes. Supa Plus couplings
AVK SUPA PUS COUPING 1/61 Tensile, for PE and PVC pipes, NF approved EPM sealing AVK Supa Plus is a range of tensile couplings, flange adaptors and end caps dedicated for PE and upvc pipes. Supa Plus couplings
Slide 1
 Dalelių filtro metodo ir vizualios odometrijos taikymas BPO lokalizacijai 2014 2018 m. studijos Doktorantas: Rokas Jurevičius Vadovas: Virginijus Marcinkevičius Disertacijos tikslas ir objektas Disertacijos
Dalelių filtro metodo ir vizualios odometrijos taikymas BPO lokalizacijai 2014 2018 m. studijos Doktorantas: Rokas Jurevičius Vadovas: Virginijus Marcinkevičius Disertacijos tikslas ir objektas Disertacijos
Microsoft Word - Deposits and withdrawals policy 400.doc
 DEPOSITS AND WITHDRAWALS POLICY / LĖŠŲ ĮDĖJIMO IR NUĖMIMO POLITIKA TeleTrade-DJ International Consulting Ltd 2011-2017 TeleTrade-DJ International Consulting Ltd. 1 Bank Wire Transfers: When depositing
DEPOSITS AND WITHDRAWALS POLICY / LĖŠŲ ĮDĖJIMO IR NUĖMIMO POLITIKA TeleTrade-DJ International Consulting Ltd 2011-2017 TeleTrade-DJ International Consulting Ltd. 1 Bank Wire Transfers: When depositing
Civilinės aviacijos administracija
 SAFA programa. Aktualūs klausimai Andrejus Golubevas Skrydžių priežiūros skyriaus vyriausiasis specialistas 2012-11-12 1 Prezentacijos turinys SAFA programos teisinis pagrindas SAFA programos principai
SAFA programa. Aktualūs klausimai Andrejus Golubevas Skrydžių priežiūros skyriaus vyriausiasis specialistas 2012-11-12 1 Prezentacijos turinys SAFA programos teisinis pagrindas SAFA programos principai
VIZOS GAVIMAS-INFO
 KAIP KREIPTIS DĖL VIZOS 1. Sumokėkite konsulinį mokestį. Kiekvieno besikreipiančio dėl vizos asmens vardu, įskaitant mažamečius vaikus ir pensininkus, turi būti sumokėtas negrąžinamas konsulinis mokestis.
KAIP KREIPTIS DĖL VIZOS 1. Sumokėkite konsulinį mokestį. Kiekvieno besikreipiančio dėl vizos asmens vardu, įskaitant mažamečius vaikus ir pensininkus, turi būti sumokėtas negrąžinamas konsulinis mokestis.
Neiškiliojo optimizavimo algoritmas su nauju bikriteriniu potencialiųjų simpleksų išrinkimu naudojant Lipšico konstantos įvertį
 Neiškiliojo optimizavimo algoritmas su nauju bikriteriniu potencialiųjų simpleksų išrinkimu naudojant Lipšico konstantos įvertį. Albertas Gimbutas 2018 m. birželio 19 d. Vadovas: Prof. habil. dr. Antanas
Neiškiliojo optimizavimo algoritmas su nauju bikriteriniu potencialiųjų simpleksų išrinkimu naudojant Lipšico konstantos įvertį. Albertas Gimbutas 2018 m. birželio 19 d. Vadovas: Prof. habil. dr. Antanas
P. Kasparaitis. Praktinė informatika. Skriptų vykdymas ir duomenų valdymas Skriptų vykdymas ir duomenų valdymas Įvadas Skripto failas tai M
 Skriptų vykdymas ir duomenų valdymas Įvadas Skripto failas tai MATLAB komandų seka, vadinama programa, įrašyta į failą. Vykdant skripto failą įvykdomos jame esančios komandos. Bus kalbama, kaip sukurti
Skriptų vykdymas ir duomenų valdymas Įvadas Skripto failas tai MATLAB komandų seka, vadinama programa, įrašyta į failą. Vykdant skripto failą įvykdomos jame esančios komandos. Bus kalbama, kaip sukurti
Slide 1
 Duomenų struktūros ir algoritmai 12 paskaita 2019-05-08 Norint kažką sukonstruoti, reikia... turėti detalių. 13 paskaitos tikslas Susipažinti su python modulio add.py 1.1 versija. Sukurti skaitmeninį modelį
Duomenų struktūros ir algoritmai 12 paskaita 2019-05-08 Norint kažką sukonstruoti, reikia... turėti detalių. 13 paskaitos tikslas Susipažinti su python modulio add.py 1.1 versija. Sukurti skaitmeninį modelį
Longse Wi-Fi kameros greito paleidimo instrukcija 1. Jums prireiks 1.1. Longse Wi-Fi kameros 1.2. Vaizdo stebėjimo kameros maitinimo šaltinio 1.3. UTP
 Longse Wi-Fi kameros greito paleidimo instrukcija 1. Jums prireiks 1.1. Longse Wi-Fi kameros 1.2. Vaizdo stebėjimo kameros maitinimo šaltinio 1.3. UTP RJ-45 interneto kabelio 1.4. Kompiuterio su prieiga
Longse Wi-Fi kameros greito paleidimo instrukcija 1. Jums prireiks 1.1. Longse Wi-Fi kameros 1.2. Vaizdo stebėjimo kameros maitinimo šaltinio 1.3. UTP RJ-45 interneto kabelio 1.4. Kompiuterio su prieiga
NEPRIKLAUSOMO AUDITORIAUS IŠVADA UAB Vilniaus gatvių apšvietimo elektros tinklai akcininkui Nuomonė Mes atlikome UAB Vilniaus gatvių apšvietimo elektr
 NEPRIKLAUSOMO AUDITORIAUS IŠVADA UAB Vilniaus gatvių apšvietimo elektros tinklai akcininkui Nuomonė Mes atlikome UAB Vilniaus gatvių apšvietimo elektros tinklai (toliau Įmonė) finansinių ataskaitų, kurias
NEPRIKLAUSOMO AUDITORIAUS IŠVADA UAB Vilniaus gatvių apšvietimo elektros tinklai akcininkui Nuomonė Mes atlikome UAB Vilniaus gatvių apšvietimo elektros tinklai (toliau Įmonė) finansinių ataskaitų, kurias
CompoundJS Node on rails
 CompoundJS Node on rails Turinys Node pristatymas Node platformos Sintaksės palyginimas Našumo palyginimas Node? Kas tai? 1 http = require("http") 2 onrequest = (request, response)-> 3 console.log("request
CompoundJS Node on rails Turinys Node pristatymas Node platformos Sintaksės palyginimas Našumo palyginimas Node? Kas tai? 1 http = require("http") 2 onrequest = (request, response)-> 3 console.log("request
PowerPoint Presentation
 Skaitmeninės kabelinės televizijos galimybės Mindaugas Žilinskas Ryšių reguliavimo tarnybos Radijo ryšio departamento direktorius Vilnius, 2012 m. 1 Turinys 1. Raiškiosios (HD) televizijos standartai ir
Skaitmeninės kabelinės televizijos galimybės Mindaugas Žilinskas Ryšių reguliavimo tarnybos Radijo ryšio departamento direktorius Vilnius, 2012 m. 1 Turinys 1. Raiškiosios (HD) televizijos standartai ir
MAGENTO 1.9 OMNIVA MODULIO DIEGIMO INSTRUKCIJA
 MAGENTO 1.9 OMNIVA MODULIO DIEGIMO INSTRUKCIJA Turinys MODULIO FUNKCIONALUMAS... 3 NAUDOJAMI TERMINAI IR SĄVOKOS... 3 REKOMENDUOJAMI NAUDOTI ĮRANKIAI... 3 ELEKTRONINĖS PARDUOTUVĖS REIKALAVIMAI... 3 SERVERIO
MAGENTO 1.9 OMNIVA MODULIO DIEGIMO INSTRUKCIJA Turinys MODULIO FUNKCIONALUMAS... 3 NAUDOJAMI TERMINAI IR SĄVOKOS... 3 REKOMENDUOJAMI NAUDOTI ĮRANKIAI... 3 ELEKTRONINĖS PARDUOTUVĖS REIKALAVIMAI... 3 SERVERIO
Register your product and get support at Indoor wireless headphones SHC8535 SHC8575 LT Vartotojo vadovas
 Register your product and get support at www.philips.com/welcome Indoor wireless headphones SHC8535 SHC8575 LT Vartotojo vadovas SHC8535 SHC8535 A a b B a c d b e f c C D E F a G b H I 1 Kas yra rinkinyje
Register your product and get support at www.philips.com/welcome Indoor wireless headphones SHC8535 SHC8575 LT Vartotojo vadovas SHC8535 SHC8535 A a b B a c d b e f c C D E F a G b H I 1 Kas yra rinkinyje
Microsoft PowerPoint - IOSrautai.ppt
 I/O - srautai OP2, ver. 2009-11-25. Paruošė: R.Vaicekauskas Turinys Srauto abstrakcija Javoje Bazinių klasių ypatybės Specializuoti srautai Srautai-filtrai. Dekoratoriaus šablonas. Objektų srautas. Serializacija.
I/O - srautai OP2, ver. 2009-11-25. Paruošė: R.Vaicekauskas Turinys Srauto abstrakcija Javoje Bazinių klasių ypatybės Specializuoti srautai Srautai-filtrai. Dekoratoriaus šablonas. Objektų srautas. Serializacija.
Slide 1
 Horizontas 2020 teminės srities Mokslas su visuomene ir visuomenei 2018 2020 m. darbo programa ir kvietimų tematika Horizontas 2020 teminės srities Mokslas su visuomene ir visuomenei informacinė diena
Horizontas 2020 teminės srities Mokslas su visuomene ir visuomenei 2018 2020 m. darbo programa ir kvietimų tematika Horizontas 2020 teminės srities Mokslas su visuomene ir visuomenei informacinė diena
Logines funkcijos termu generavimo algoritmas pagristas funkciniu modeliu
 KAUNO TECHNOLOGIJOS UNIVERSITETAS INFORMATIKOS FAKULTETAS PROGRAMŲ INŽINERIJOS KATEDRA Tomas Žemaitis LOGINĖS FUNKCIJOS TERMŲ GENERAVIMO ALGORITMAS PAGRĮSTAS PROGRAMINIO PROTOTIPO MODELIU Magistro darbas
KAUNO TECHNOLOGIJOS UNIVERSITETAS INFORMATIKOS FAKULTETAS PROGRAMŲ INŽINERIJOS KATEDRA Tomas Žemaitis LOGINĖS FUNKCIJOS TERMŲ GENERAVIMO ALGORITMAS PAGRĮSTAS PROGRAMINIO PROTOTIPO MODELIU Magistro darbas
MUITINĖS DEPARTAMENTAS PRIE LIETUVOS RESPUBLIKOS FINANSŲ MINISTERIJOS BENDRO NAUDOTOJŲ VALDYMO SISTEMOS, ATITINKANČIOS EUROPOS KOMISIJOS REIKALAVIMUS,
 MUITINĖS DEPARTAMENTAS PRIE LIETUVOS RESPUBLIKOS FINANSŲ MINISTERIJOS BENDRO NAUDOTOJŲ VALDYMO SISTEMOS, ATITINKANČIOS EUROPOS KOMISIJOS REIKALAVIMUS, SUKŪRIMO VERSIJA: v0.10 Vilnius 2018 TURINYS 1 Windows
MUITINĖS DEPARTAMENTAS PRIE LIETUVOS RESPUBLIKOS FINANSŲ MINISTERIJOS BENDRO NAUDOTOJŲ VALDYMO SISTEMOS, ATITINKANČIOS EUROPOS KOMISIJOS REIKALAVIMUS, SUKŪRIMO VERSIJA: v0.10 Vilnius 2018 TURINYS 1 Windows
Algoritmai ir duomenų struktūros (ADS) 7 paskaita Saulius Ragaišis, VU MIF
 7 paskaita Saulius Ragaišis, VU MIF") Algoritmai ir duomenų struktūros (ADS) 7 paskaita Saulius Ragaišis, VU MIF saulius.ragaisis@mif.vu.lt 2015-04-13 Grafai Grafas aibių pora (V, L). V viršūnių (vertex) aibė, L briaunų (edge) aibė Briauna
Algoritmai ir duomenų struktūros (ADS) 7 paskaita Saulius Ragaišis, VU MIF saulius.ragaisis@mif.vu.lt 2015-04-13 Grafai Grafas aibių pora (V, L). V viršūnių (vertex) aibė, L briaunų (edge) aibė Briauna
Technines specifikacijos projektas
 KOMPIUTERINĖS IR PROGRAMINĖS ĮRANGOS PIRKIMO TECHNINĖS SPECIFIKACIJOS PROJEKTAS 1. Perkančioji organizacija Lietuvos teismo ekspertizės centras, biudžetinė įstaiga, kurios duomenys kaupiami saugomi Juridinių
KOMPIUTERINĖS IR PROGRAMINĖS ĮRANGOS PIRKIMO TECHNINĖS SPECIFIKACIJOS PROJEKTAS 1. Perkančioji organizacija Lietuvos teismo ekspertizės centras, biudžetinė įstaiga, kurios duomenys kaupiami saugomi Juridinių
SPECIALIOSIOS UŽDAROJO TIPO PRIVATAUS KAPITALO INVESTICINĖS BENDROVĖS INVL TECHNOLOGY AUDITO KOMITETO NUOSTATAI BENDROJI DALIS 1. Šie specialiosios už
 SPECIALIOSIOS UŽDAROJO TIPO PRIVATAUS KAPITALO INVESTICINĖS BENDROVĖS INVL TECHNOLOGY AUDITO KOMITETO NUOSTATAI BENDROJI DALIS 1. Šie specialiosios uždarojo tipo privataus kapitalo investicinės bendrovės
SPECIALIOSIOS UŽDAROJO TIPO PRIVATAUS KAPITALO INVESTICINĖS BENDROVĖS INVL TECHNOLOGY AUDITO KOMITETO NUOSTATAI BENDROJI DALIS 1. Šie specialiosios uždarojo tipo privataus kapitalo investicinės bendrovės
Pagrindiniai algoritmai dirbant su sveikųjų ir realiųjų skaičių masyvų reikšmėmis Sumos skaičiavimo algoritmas Sveikieji skaičiai int Suma (int X[], i
![Pagrindiniai algoritmai dirbant su sveikųjų ir realiųjų skaičių masyvų reikšmėmis Sumos skaičiavimo algoritmas Sveikieji skaičiai int Suma (int X[], i](/thumbs/88/116318386.jpg "Pagrindiniai algoritmai dirbant su sveikųjų ir realiųjų skaičių masyvų reikšmėmis Sumos skaičiavimo algoritmas Sveikieji skaičiai int Suma (int X[], i") Pagrindiniai algoritmai dirbant su sveikųjų ir realiųjų skaičių masyvų reikšmėmis Sumos skaičiavimo algoritmas int Suma (int X[], int n) int s = 0; s = s + X[i]; return s; double Suma (double X[], int
Pagrindiniai algoritmai dirbant su sveikųjų ir realiųjų skaičių masyvų reikšmėmis Sumos skaičiavimo algoritmas int Suma (int X[], int n) int s = 0; s = s + X[i]; return s; double Suma (double X[], int
Slide 1
 H2020 Pažangos sklaida ir dalyvavimo plėtra Informacinis renginys, Lietuvos mokslo taryba Živilė Ruželė, zivile.ruzele@lmt.lt 2019 m. birželio 7 d. Turinys 1. Plėtros stipendijos 2. Patarimai Twinning
H2020 Pažangos sklaida ir dalyvavimo plėtra Informacinis renginys, Lietuvos mokslo taryba Živilė Ruželė, zivile.ruzele@lmt.lt 2019 m. birželio 7 d. Turinys 1. Plėtros stipendijos 2. Patarimai Twinning
Microsoft Word - SDH2.doc
 PATVIRTINTA AB Lietuvos geleţinkeliai Geleţinkelių infrastruktūros direkcijos direktoriaus 2009-11-30 įsakymu Nr. Į (DI-161) SDH SĄSAJOS TECHNINIS APRAŠAS TURINYS I. BENDROJI DALIS... 4 II. TAIKYMO SRITIS...
PATVIRTINTA AB Lietuvos geleţinkeliai Geleţinkelių infrastruktūros direkcijos direktoriaus 2009-11-30 įsakymu Nr. Į (DI-161) SDH SĄSAJOS TECHNINIS APRAŠAS TURINYS I. BENDROJI DALIS... 4 II. TAIKYMO SRITIS...
skaitiniai metodai 1
 Lygiagretusis programavimas doc. dr. Vadimas Starikovičius 7-oji paskaita Aukštesnio lygio MPI konstrukcijos. Įvairūs duomenų siuntimo būdai. Kolektyvinės duomenų persiuntimo operacijos (funkcijos). Šešios
Lygiagretusis programavimas doc. dr. Vadimas Starikovičius 7-oji paskaita Aukštesnio lygio MPI konstrukcijos. Įvairūs duomenų siuntimo būdai. Kolektyvinės duomenų persiuntimo operacijos (funkcijos). Šešios
Layout 1
 Kvalifikacijos kėlimo kursų programos Pneumatika Pneumatikos pagrindai mašinų operatoriams P100 Suteikite savo mašinų operatoriams įgūdžių optimalaus darbinio slėgio nustatymui, oro pratekėjimų (nuostolių)
Kvalifikacijos kėlimo kursų programos Pneumatika Pneumatikos pagrindai mašinų operatoriams P100 Suteikite savo mašinų operatoriams įgūdžių optimalaus darbinio slėgio nustatymui, oro pratekėjimų (nuostolių)
4 skyrius Algoritmai grafuose 4.1. Grafų teorijos uždaviniai Grafai Tegul turime viršūnių aibę V = { v 1,v 2,...,v N } (angl. vertex) ir briaun
 ir briaun") skyrius Algoritmai grafuose.. Grafų teorijos uždaviniai... Grafai Tegul turime viršūnių aibę V = { v,v,...,v N (angl. vertex) ir briaunų aibę E = { e,e,...,e K, briauna (angl. edge) yra viršūnių pora ej
skyrius Algoritmai grafuose.. Grafų teorijos uždaviniai... Grafai Tegul turime viršūnių aibę V = { v,v,...,v N (angl. vertex) ir briaunų aibę E = { e,e,...,e K, briauna (angl. edge) yra viršūnių pora ej
Techninė dokumentacija Qlik Sense architektūros apžvalga 2015 m. gruodis qlik.com
 Techninė dokumentacija Qlik Sense architektūros apžvalga 2015 m. gruodis qlik.com Platforma Qlik Sense tai analitikos platforma, naudojanti asociatyvinį analitikos variklį operatyvinėje atmintyje. Remiantis
Techninė dokumentacija Qlik Sense architektūros apžvalga 2015 m. gruodis qlik.com Platforma Qlik Sense tai analitikos platforma, naudojanti asociatyvinį analitikos variklį operatyvinėje atmintyje. Remiantis
Hexagonal Architecture with Ruby on Rails - Šiašiakampe architektura su Ruby on Rails
 Hexagonal Architecture with Ruby on Rails Šiašiakampė architektūra su Ruby on Rails Vilius Luneckas vilius.luneckas@gmail.com #3 Ruby Meetup 2013 Vilius Luneckas #3 Ruby Meetup Hexagonal Architecture with
Hexagonal Architecture with Ruby on Rails Šiašiakampė architektūra su Ruby on Rails Vilius Luneckas vilius.luneckas@gmail.com #3 Ruby Meetup 2013 Vilius Luneckas #3 Ruby Meetup Hexagonal Architecture with
Klausimas: Could you please provide clarity to one section of the tender document? In the document it states (using a google translator) Before enteri
 Before enteri") Klausimas: Could you please provide clarity to one section of the tender document? In the document it states (using a google translator) Before entering the Tender, the Tenderer must transfer to the LOU
Klausimas: Could you please provide clarity to one section of the tender document? In the document it states (using a google translator) Before entering the Tender, the Tenderer must transfer to the LOU
DARBO SUTARTIS
 PATVIRTINTA Lietuvos Respublikos švietimo ir mokslo ministro 2016 m. lapkričio 16 d. įsakymu Nr. V-1011 (Studento praktinio mokymo sutarties pavyzdinė forma) STUDENTO PRAKTINIO MOKYMO PAVYZDINĖ SUTARTIS
PATVIRTINTA Lietuvos Respublikos švietimo ir mokslo ministro 2016 m. lapkričio 16 d. įsakymu Nr. V-1011 (Studento praktinio mokymo sutarties pavyzdinė forma) STUDENTO PRAKTINIO MOKYMO PAVYZDINĖ SUTARTIS
Algoritmø analizës specialieji skyriai
 VGTU Matematinio modeliavimo katedra VGTU SC Lygiagrečiųjų skaičiavimų laboratorija Paskaitų kursas. 5-oji dalis. Turinys 1 2 KPU euristiniai sprendimo algoritmai KPU sprendimas dinaminio programavimo
VGTU Matematinio modeliavimo katedra VGTU SC Lygiagrečiųjų skaičiavimų laboratorija Paskaitų kursas. 5-oji dalis. Turinys 1 2 KPU euristiniai sprendimo algoritmai KPU sprendimas dinaminio programavimo
Slide 1
 Elektroninių įrenginių gamintojai Apie įmonę V. Bartkevičiaus įmonė Valsena buvo įkurta 1996 Birželio 4 dieną. Pagrindinė įmonės veikla unikalių mikroprocesorinių duomenų perdavimo prietaisų projektavimas
Elektroninių įrenginių gamintojai Apie įmonę V. Bartkevičiaus įmonė Valsena buvo įkurta 1996 Birželio 4 dieną. Pagrindinė įmonės veikla unikalių mikroprocesorinių duomenų perdavimo prietaisų projektavimas
PowerPoint Presentation
 Duomenų archyvai ir mokslo duomenų valdymo planai 2018-06-13 1 Re3Data duomenų talpyklų registras virš 2000 mokslinių tyrimų duomenų talpyklų; talpyklos paiešką galima atlikti pagal mokslo kryptį, šalį,
Duomenų archyvai ir mokslo duomenų valdymo planai 2018-06-13 1 Re3Data duomenų talpyklų registras virš 2000 mokslinių tyrimų duomenų talpyklų; talpyklos paiešką galima atlikti pagal mokslo kryptį, šalį,
RR-GSM_IM_LT_110125
 Retransliatorius RR-GSM Įrengimo instrukcija Draugystės g. 17, LT-51229 Kaunas El. p.: info@trikdis.lt www.trikdis.lt Retransliatorius RR-GSM perduoda priimtus pranešimus į centralizuoto stebėjimo pultą
Retransliatorius RR-GSM Įrengimo instrukcija Draugystės g. 17, LT-51229 Kaunas El. p.: info@trikdis.lt www.trikdis.lt Retransliatorius RR-GSM perduoda priimtus pranešimus į centralizuoto stebėjimo pultą
Hands-on exercise
 Patvirtinamasis dokumentas 1 (4) 2017 m. gegužės 25 d. Praktinė užduotis Su sprendiniais 1 Turinys 1. Įvadas... 2 2. Instrukcijos... 2 2.1. Sutartiniai ženklai... 2 2.2. Užduoties etapai... 2 3. Užduoties
Patvirtinamasis dokumentas 1 (4) 2017 m. gegužės 25 d. Praktinė užduotis Su sprendiniais 1 Turinys 1. Įvadas... 2 2. Instrukcijos... 2 2.1. Sutartiniai ženklai... 2 2.2. Užduoties etapai... 2 3. Užduoties
Atviro konkurso sąlygų 4 priedas BENDROJO PAGALBOS CENTRO INFORMACINĖS SISTEMOS APTARNAVIMO PASLAUGŲ TEIKIMO SPECIFIKACIJA 1. Pirkimo objektas Bendroj
 Atviro konkurso sąlygų 4 priedas BENDROJO PAGALBOS CENTRO INFORMACINĖS SISTEMOS APTARNAVIMO PASLAUGŲ TEIKIMO SPECIFIKACIJA 1. Pirkimo objektas Bendrojo pagalbos centro informacinės sistemos BPCIS, esančios
Atviro konkurso sąlygų 4 priedas BENDROJO PAGALBOS CENTRO INFORMACINĖS SISTEMOS APTARNAVIMO PASLAUGŲ TEIKIMO SPECIFIKACIJA 1. Pirkimo objektas Bendrojo pagalbos centro informacinės sistemos BPCIS, esančios
2019 m. LIETUVOS RESPUBLIKOS BURIAVIMO TAURĖS REGATA BEI VLADIMIRO IR VALERIJAUS MAMONTOVŲ ATMINIMO VĖTRUNGĖS TAURĖ d. NIDA, Lietuva LEN
 2019 m. LIETUVOS RESPUBLIKOS BURIAVIMO TAURĖS REGATA BEI VLADIMIRO IR VALERIJAUS MAMONTOVŲ ATMINIMO VĖTRUNGĖS TAURĖ 2019 05 10-12 d. NIDA, Lietuva LENKTYNIŲ INSTRUKCIJA LITHUANIAN SAILING CUP REGATTA 2019
2019 m. LIETUVOS RESPUBLIKOS BURIAVIMO TAURĖS REGATA BEI VLADIMIRO IR VALERIJAUS MAMONTOVŲ ATMINIMO VĖTRUNGĖS TAURĖ 2019 05 10-12 d. NIDA, Lietuva LENKTYNIŲ INSTRUKCIJA LITHUANIAN SAILING CUP REGATTA 2019
Vertimas iš anglų kalbos Question: Could you please provide clarity to one section of the tender document? In the document it states (using a google t
 Vertimas iš anglų kalbos Question: Could you please provide clarity to one section of the tender document? In the document it states (using a google translator) Before entering the Tender, the Tenderer
Vertimas iš anglų kalbos Question: Could you please provide clarity to one section of the tender document? In the document it states (using a google translator) Before entering the Tender, the Tenderer
Lietuvos mokslo ir studijų institucijų kompiuterių tinklas LITNET Vilniaus universitetas Mokslininko darbo vietos paslauga Paslaugos naudojimo instruk
 Lietuvos mokslo ir studijų institucijų kompiuterių tinklas LITNET Vilniaus universitetas Mokslininko darbo vietos paslauga Paslaugos naudojimo instrukcija Paslauga sukurta vykdant Europos socialinio fondo
Lietuvos mokslo ir studijų institucijų kompiuterių tinklas LITNET Vilniaus universitetas Mokslininko darbo vietos paslauga Paslaugos naudojimo instrukcija Paslauga sukurta vykdant Europos socialinio fondo
LIETUVOS RESPUBLIKOS VALSTYBINIO PATENTŲ BIURO DIREKTORIAUS
 Įsakymas netenka galios 2015-11-24: Lietuvos Respublikos valstybinis patentų biuras, Įsakymas Nr. 3R-72, 2015-11-20, paskelbta TAR 2015-11-23, i. k. 2015-18546 Dėl Lietuvos Respublikos valstybinio patentų
Įsakymas netenka galios 2015-11-24: Lietuvos Respublikos valstybinis patentų biuras, Įsakymas Nr. 3R-72, 2015-11-20, paskelbta TAR 2015-11-23, i. k. 2015-18546 Dėl Lietuvos Respublikos valstybinio patentų
PowerPoint Presentation
 Algoritmai ir duomenų struktūros (ADS) 15 paskaita Saulius Ragaišis, VU MIF saulius.ragaisis@mif.vu.lt 2018-05-28 Grįžtamasis ryšys Ačiū visiems dalyvavusiems Daug pagyrimų Ačiū, bet jie nepadeda tobulėti.
Algoritmai ir duomenų struktūros (ADS) 15 paskaita Saulius Ragaišis, VU MIF saulius.ragaisis@mif.vu.lt 2018-05-28 Grįžtamasis ryšys Ačiū visiems dalyvavusiems Daug pagyrimų Ačiū, bet jie nepadeda tobulėti.
LIETUVOS RESPUBLIKOS ŪKIO MINISTRAS
 LIETUVOS RESPUBLIKOS ENERGETIKOS MINISTERIJA 2014 2020 M. EUROPOS SĄJUNGOS FONDŲ INVESTICIJŲ VEIKSMŲ PROGRAMOS PRIORITETO ĮGYVENDINIMO PRIEMONIŲ ĮGYVENDINIMO PLANAS I SKYRIUS 2014 2020 M. EUROPOS SĄJUNGOS
LIETUVOS RESPUBLIKOS ENERGETIKOS MINISTERIJA 2014 2020 M. EUROPOS SĄJUNGOS FONDŲ INVESTICIJŲ VEIKSMŲ PROGRAMOS PRIORITETO ĮGYVENDINIMO PRIEMONIŲ ĮGYVENDINIMO PLANAS I SKYRIUS 2014 2020 M. EUROPOS SĄJUNGOS
Muzikos duomenų bazės NAXOS Music Library naudojimo vadovas Turinys Kas yra NAXOS Music Library... 2 Kaip pradėti naudotis... 3 Kaip atlikti paiešką..
 Muzikos duomenų bazės NAXOS Music Library naudojimo vadovas Turinys Kas yra NAXOS Music Library... 2 Kaip pradėti naudotis... 3 Kaip atlikti paiešką... 3 Paprastoji paieška... 3 Išplėstinė paieška... 3
Muzikos duomenų bazės NAXOS Music Library naudojimo vadovas Turinys Kas yra NAXOS Music Library... 2 Kaip pradėti naudotis... 3 Kaip atlikti paiešką... 3 Paprastoji paieška... 3 Išplėstinė paieška... 3
Printing triistr.wxmx
 triistr.wxmx / Triįstrižainių lygčių sistemų sprendimas A.Domarkas, VU, Teoriją žr. []; [], 7-7; []. Pradžioje naudosime Gauso algoritmą, kuriame po įstrižaine daromi nuliai. Po to grįždami į viršų virš
triistr.wxmx / Triįstrižainių lygčių sistemų sprendimas A.Domarkas, VU, Teoriją žr. []; [], 7-7; []. Pradžioje naudosime Gauso algoritmą, kuriame po įstrižaine daromi nuliai. Po to grįždami į viršų virš
PRESENTATION NAME
 Energiją generuojantys CŠT vartotojai: technologijos ir įdiegtų sistemų pavyzdžiai dr. Rokas Valančius rokas.valancius@ktu.lt Kaunas, 2019 PRANEŠIMO TURINYS: Pastatų energijos poreikiai Alternatyvūs energijos
Energiją generuojantys CŠT vartotojai: technologijos ir įdiegtų sistemų pavyzdžiai dr. Rokas Valančius rokas.valancius@ktu.lt Kaunas, 2019 PRANEŠIMO TURINYS: Pastatų energijos poreikiai Alternatyvūs energijos
Dažniausios IT VBE klaidos
 Dažniausios IT VBE klaidos Renata Burbaitė renata.burbaite@gmail.com Kauno technologijos universitetas, Panevėžio Juozo Balčikonio gimnazija 1 Egzamino matrica (iš informacinių technologijų brandos egzamino
Dažniausios IT VBE klaidos Renata Burbaitė renata.burbaite@gmail.com Kauno technologijos universitetas, Panevėžio Juozo Balčikonio gimnazija 1 Egzamino matrica (iš informacinių technologijų brandos egzamino
Microsoft PowerPoint - Siaulys_Tomas.ppt [Tik skaityti]
![Microsoft PowerPoint - Siaulys_Tomas.ppt [Tik skaityti]](/thumbs/88/116266152.jpg "Microsoft PowerPoint - Siaulys_Tomas.ppt [Tik skaityti]") VILNIAUS LICĖJUS Tomas Šiaulys Second Life taikymas švietime Tarptautinė konferencija Mokymosi bendruomenė ir antrosios kartos saityno (Web 2.0) technologijos VILNIUS 2010 2 Apie Second Life Nemokamai
VILNIAUS LICĖJUS Tomas Šiaulys Second Life taikymas švietime Tarptautinė konferencija Mokymosi bendruomenė ir antrosios kartos saityno (Web 2.0) technologijos VILNIUS 2010 2 Apie Second Life Nemokamai
Pofsajungu_gidas_Nr11.pdf
 2 p. 3 p. 4 p. Šiame straipsnyje pristatoma profsąjungų svarba ir galimos jų veiklos kryptys, kovojant su diskriminacija darbo rinkoje. Ši profesinių sąjungų veiklos sritis reikšminga ne tik socialiai
2 p. 3 p. 4 p. Šiame straipsnyje pristatoma profsąjungų svarba ir galimos jų veiklos kryptys, kovojant su diskriminacija darbo rinkoje. Ši profesinių sąjungų veiklos sritis reikšminga ne tik socialiai
LIETUVOS RESPUBLIKOS FINANSŲ MINISTRAS ĮSAKYMAS DĖL FINANSŲ MINISTRO 2014 M. GRUODŽIO 30 D. ĮSAKYMO NR. 1K-499 DĖL METŲ EUROPOS SĄJUNGOS FON
 LIETUVOS RESPUBLIKOS FINANSŲ MINISTRAS ĮSAKYMAS DĖL FINANSŲ MINISTRO 2014 M. GRUODŽIO 30 D. ĮSAKYMO NR. 1K-499 DĖL 2014 2020 METŲ EUROPOS SĄJUNGOS FONDŲ INVESTICIJŲ VEIKSMŲ PROGRAMOS STEBĖSENOS RODIKLIŲ
LIETUVOS RESPUBLIKOS FINANSŲ MINISTRAS ĮSAKYMAS DĖL FINANSŲ MINISTRO 2014 M. GRUODŽIO 30 D. ĮSAKYMO NR. 1K-499 DĖL 2014 2020 METŲ EUROPOS SĄJUNGOS FONDŲ INVESTICIJŲ VEIKSMŲ PROGRAMOS STEBĖSENOS RODIKLIŲ
Cloud_sprendimu_salygos.pdf
 Sąvokos: SPECIALIOSIOS PUBLIC CLOUD INSTANCE PASLAUGOS NAUDOJIMO SĄLYGOS Versija: 2012-06-11 GAMA VERSIJA API (Application Programming Interface): Taikomojo programavimo sąsaja, kurią naudodamas Klientas
Sąvokos: SPECIALIOSIOS PUBLIC CLOUD INSTANCE PASLAUGOS NAUDOJIMO SĄLYGOS Versija: 2012-06-11 GAMA VERSIJA API (Application Programming Interface): Taikomojo programavimo sąsaja, kurią naudodamas Klientas
Techninis aprašymas SONOMETER TM 1100 Ultragarsinis kompaktiškas energijos skaitiklis Aprašymas / taikymas MID tikrinimo sertifikato nr.: DE-10-MI004-
 SONOMETER TM 1100 Ultragarsinis kompaktiškas energijos skaitiklis Aprašymas / taikymas MID tikrinimo sertifikato nr.: DE-10-MI004-PTB003 SONOMETER 1100 tai ultragarsinis statinis kompaktiškas energijos
SONOMETER TM 1100 Ultragarsinis kompaktiškas energijos skaitiklis Aprašymas / taikymas MID tikrinimo sertifikato nr.: DE-10-MI004-PTB003 SONOMETER 1100 tai ultragarsinis statinis kompaktiškas energijos
Slide 1
 Duomenų struktūros ir algoritmai 1 paskaita 2019-02-06 Kontaktai Martynas Sabaliauskas (VU MIF DMSTI) El. paštas: akatasis@gmail.com arba martynas.sabaliauskas@mii.vu.lt Rėmai mokykloje Rėmai aukštojoje
Duomenų struktūros ir algoritmai 1 paskaita 2019-02-06 Kontaktai Martynas Sabaliauskas (VU MIF DMSTI) El. paštas: akatasis@gmail.com arba martynas.sabaliauskas@mii.vu.lt Rėmai mokykloje Rėmai aukštojoje
PowerPoint Presentation
 SG Dujos Kelias pirmyn 29TH SEPTEMBER 2014, EU DIRECTIVE ON THE DEPLOYMENT OF AN ALTERNATIVE FUELS INFRASTRUCTURE SETS THE RULES FOR ENSURING MINIMUM COVERAGE OF REFUELING POINTS FOR ALTERNATIVE FUELS
SG Dujos Kelias pirmyn 29TH SEPTEMBER 2014, EU DIRECTIVE ON THE DEPLOYMENT OF AN ALTERNATIVE FUELS INFRASTRUCTURE SETS THE RULES FOR ENSURING MINIMUM COVERAGE OF REFUELING POINTS FOR ALTERNATIVE FUELS
rp_ IS_2
 Page 1 of 5 Pagrindinė informacija Juodoji aromatizuota arbata su miško uogomis Exemption Flags Exempt from Artwork Exempt from NEP Reporting Produkto pavadinimas Country Lipton Brand Name Forest Fruits
Page 1 of 5 Pagrindinė informacija Juodoji aromatizuota arbata su miško uogomis Exemption Flags Exempt from Artwork Exempt from NEP Reporting Produkto pavadinimas Country Lipton Brand Name Forest Fruits
STUDENTŲ, ATRINKTŲ ERASMUS+ STUDIJOMS SU STIPENDIJA, SĄRAŠAS/ LIST OF STUDENTS THAT HAVE BEEN AWARDED WITH ERASMUS+ SCHOLARSHIPS Nr. Fakultetas/ Facul
 STUDENTŲ, ATRINKTŲ ERASMUS+ STUDIJOMS SU STIPENDIJA, SĄRAŠAS/ LIST OF STUDENTS THAT HAVE BEEN AWARDED WITH ERASMUS+ SCHOLARSHIPS Nr. Fakultetas/ Faculty Prašymo numeris / Application number Mokslo ir studijų
STUDENTŲ, ATRINKTŲ ERASMUS+ STUDIJOMS SU STIPENDIJA, SĄRAŠAS/ LIST OF STUDENTS THAT HAVE BEEN AWARDED WITH ERASMUS+ SCHOLARSHIPS Nr. Fakultetas/ Faculty Prašymo numeris / Application number Mokslo ir studijų
PR_COD_1amCom
 Europos Parlamentas 2014-2019 Piliečių laisvių, teisingumo ir vidaus reikalų komitetas 2016/0225(COD) 23.3.2017 ***I PRANEŠIMO PROJEKTAS dėl pasiūlymo dėl Europos Parlamento ir Tarybos reglamento, kuriuo
Europos Parlamentas 2014-2019 Piliečių laisvių, teisingumo ir vidaus reikalų komitetas 2016/0225(COD) 23.3.2017 ***I PRANEŠIMO PROJEKTAS dėl pasiūlymo dėl Europos Parlamento ir Tarybos reglamento, kuriuo
BENDROJI INFORMACIJA
 GYVENIMO APRAŠYMAS BENDROJI INFORMACIJA Vardas: Pavardė: Mokslinis vardas ir laipsnis: Pareigos: Mindaugas Krutinis Docentas, technologijos mokslų daktaras Docentas Telefono numeris: +370 656 32656 El.
GYVENIMO APRAŠYMAS BENDROJI INFORMACIJA Vardas: Pavardė: Mokslinis vardas ir laipsnis: Pareigos: Mindaugas Krutinis Docentas, technologijos mokslų daktaras Docentas Telefono numeris: +370 656 32656 El.
KTU BIBLIOTEKOS PASLAUGOS
 KTU BIBLIOTEKOS PASLAUGOS K T U B I B L I O T E K A Centrinė biblioteka K. Donelaičio g. 20 1. 2. 3. Cheminės technologijos fakulteto biblioteka Radvilėnų pl. 19 5. 4. Informatikos fakulteto biblioteka
KTU BIBLIOTEKOS PASLAUGOS K T U B I B L I O T E K A Centrinė biblioteka K. Donelaičio g. 20 1. 2. 3. Cheminės technologijos fakulteto biblioteka Radvilėnų pl. 19 5. 4. Informatikos fakulteto biblioteka
Microsoft Word asis TAS.DOC
 Tarptautinių audito ir užtikrinimo standartų valdyba 501-asis TAS 2009 balandis Tarptautinis audito standartas Audito įrodymai konkretūs svarstymai dėl atskirų sričių 1 International Auditing and Assurance
Tarptautinių audito ir užtikrinimo standartų valdyba 501-asis TAS 2009 balandis Tarptautinis audito standartas Audito įrodymai konkretūs svarstymai dėl atskirų sričių 1 International Auditing and Assurance
UAB Utenos šilumos tinklai (šilumos tiekėjo ir (ar) karšto vandens tiekėjo pavadinimas) įm.k , PVM mokėtojo kodas LT , Pramonės g. 11
 karšto vandens tiekėjo pavadinimas) įm.k , PVM mokėtojo kodas LT , Pramonės g. 11") UAB Utenos šilumos tinklai (šilumos tiekėjo ir (ar) karšto vandens tiekėjo pavadinimas) įm.k.183843314, PVM mokėtojo kodas LT838433113, Pramonės g. 11, LT-28216 Utena, tel. (8 389) 63 641, faks. (8 389)
UAB Utenos šilumos tinklai (šilumos tiekėjo ir (ar) karšto vandens tiekėjo pavadinimas) įm.k.183843314, PVM mokėtojo kodas LT838433113, Pramonės g. 11, LT-28216 Utena, tel. (8 389) 63 641, faks. (8 389)
Title
 Šiuolaikiškos ir labiau visai Europai pritaikytos autorių teisių sistemos kūrimas Vita Juknė Europos Komisijos Ryšių tinklų, turinio ir technologijų skyrius Išsakyta nuomonė yra asmeninė ir negali būti
Šiuolaikiškos ir labiau visai Europai pritaikytos autorių teisių sistemos kūrimas Vita Juknė Europos Komisijos Ryšių tinklų, turinio ir technologijų skyrius Išsakyta nuomonė yra asmeninė ir negali būti
DĖL APLINKOS IR SVEIKATOS MOKSLO KOMITETO ĮSTEIGIMO
 LIETUVOS RESPUBLIKOS SVEIKATOS APSAUGOS MINISTRAS ĮSAKYMAS DĖL LIETUVOS RESPUBLIKOS SVEIKATOS APSAUGOS MINISTRO 011 M. KOVO D. ĮSAKYMO NR. V-199 DĖL LIETUVOS HIGIENOS NORMOS HN 80:011 ELEKTROMAGNETINIS
LIETUVOS RESPUBLIKOS SVEIKATOS APSAUGOS MINISTRAS ĮSAKYMAS DĖL LIETUVOS RESPUBLIKOS SVEIKATOS APSAUGOS MINISTRO 011 M. KOVO D. ĮSAKYMO NR. V-199 DĖL LIETUVOS HIGIENOS NORMOS HN 80:011 ELEKTROMAGNETINIS
RET2000 Elektronisis Skaitmeninis Termostatas su LCD
 MAKING MODERN LIVING POSSIBLE RET2000 B/M/MS Elektroninis skaitmeninis termostatas su LCD Danfoss Heating Montavimo vadovas Norėdami gauti išsamią spausdintą šių instrukcijų versiją, skambinkite Rinkodaros
MAKING MODERN LIVING POSSIBLE RET2000 B/M/MS Elektroninis skaitmeninis termostatas su LCD Danfoss Heating Montavimo vadovas Norėdami gauti išsamią spausdintą šių instrukcijų versiją, skambinkite Rinkodaros